Beyond Binary Erasure: Soft-Weighted Unlearning for Fairness and Robustnessedit
AAAI 2026 paper on soft-weighted unlearning for fairness and robustness correction.
Beyond Binary Erasure: Soft-Weighted Unlearning for Fairness and Robustness is an AAAI 2026 conference paper by Xinbao Qiao, Ningning Ding, Yushi Cheng, and Meng Zhang. It reframes unlearning as a continuous correction problem rather than only a binary erasure operation.
Overviewedit
The paper studies a mismatch between privacy-driven unlearning and correction-driven unlearning. In a right-to-be-forgotten setting, binary deletion is natural: a sample is either retained or removed. In fairness and robustness correction, however, the goal is often to reduce harmful influence without discarding useful signal.
The paper names the resulting failure mode over-unlearning: hard deletion can improve a target fairness or robustness metric while degrading utility, flipping bias in the opposite direction, or treating borderline samples as if they were highly detrimental.
Methodedit
The method replaces binary deletion weights with continuous sample weights. It first estimates each sample's influence on both the target metric and utility, then solves a convex quadratic program for a tailored weight vector. The resulting weights are plugged into influence-function-style unlearning or related correction methods, so harmful samples can be downweighted without being treated as equally removable.
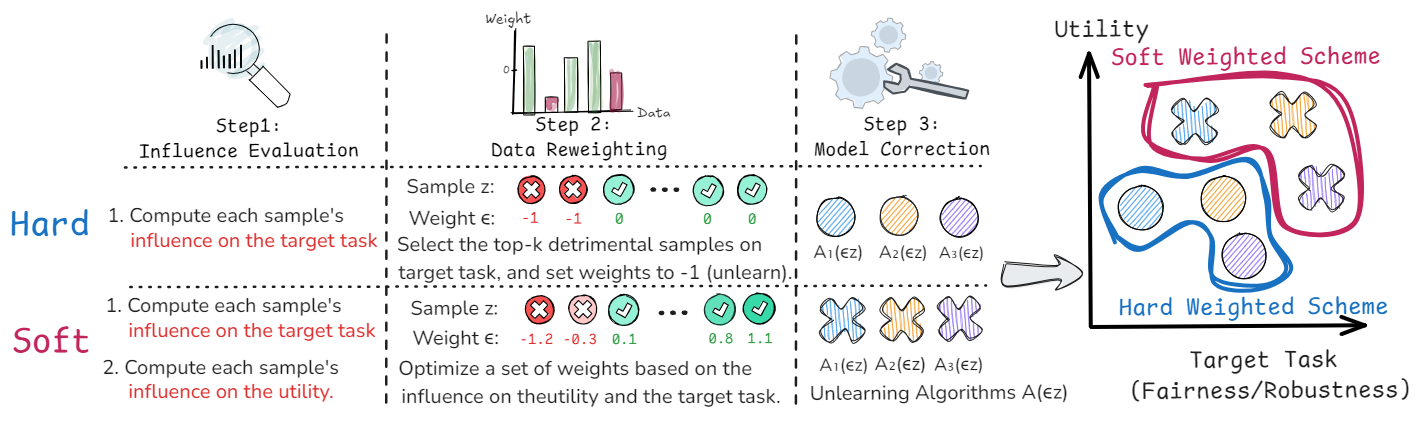
The three-stage workflow is:
- estimate each sample's influence on fairness or robustness and on utility;
- solve for continuous weights that improve the target metric while constraining utility loss;
- apply a weighted model correction instead of deleting a fixed top-k set.
Key formulaedit
The paper's optimization can be summarized as a constrained reweighting problem. denotes a sample's influence on the fairness or robustness objective, and denotes its influence on utility.
The soft deletion weights solve a regularized correction problem:
subject to:
The resulting model correction follows an influence-function update:
The constraints distinguish this approach from hard top-k deletion: the target metric must improve, but the update is not allowed to pay for that improvement through avoidable utility degradation.
Resultsedit
The experiments evaluate fairness and robustness settings across tabular, image, and text datasets, including Adult, Bank, Jigsaw, CelebA, and CIFAR-based robustness evaluations in the owner-provided paper package. The paper reports that soft-weighted variants improve fairness or robustness metrics more consistently than hard-weighted schemes while reducing the loss in utility.
The diagnostic experiments also support the premise of the method: leave-one-out and influence-based analyses show that samples harmful to a target metric are not uniformly harmful to utility. This explains why the binary "remove or keep" rule is too coarse for correction-driven unlearning.
Placementedit
This work belongs to Machine Unlearning, Fairness and Robustness, Influence Functions, and Trustworthy AI. It complements Hessian-Free Online Certified Unlearning by shifting the problem from certified privacy deletion to fine-grained model correction.