DynFrs: An Efficient Framework for Machine Unlearning in Random Forestedit
ICLR 2025 paper on efficient machine unlearning for random forests.
DynFrs: An Efficient Framework for Machine Unlearning in Random Forest is an ICLR 2025 conference paper by Shurong Wang, Zhuoyang Shen, Xinbao Qiao, Tongning Zhang, and Meng Zhang. The work targets exact and efficient data removal for random-forest models under dynamic online updates.
Overviewedit
The paper studies exact and efficient machine unlearning for random forests. Random forests are still widely used in privacy-sensitive domains such as healthcare, finance, and recommendation, but their tree-ensemble structure makes standard gradient-based unlearning tools inapplicable.
DynFrs targets three online operations on a forest: prediction, sample removal, and sample addition. The key design goal is low-latency modification without losing the distributional equivalence required by exact unlearning. The paper therefore treats unlearning as a data-structure and randomized-algorithm problem, not only as a model-update problem.
Methodedit
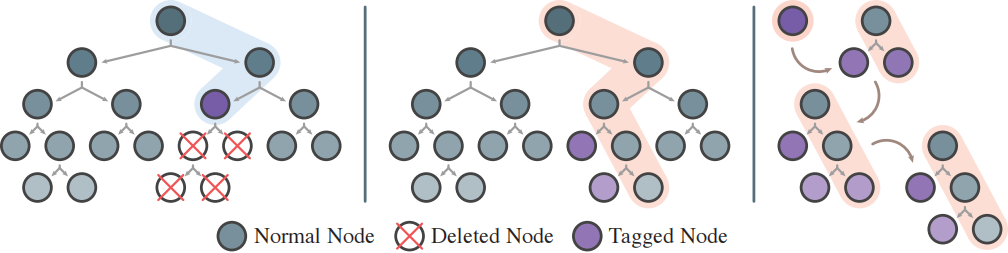
DynFrs combines three mechanisms:
- OCC(q), a tree-subsampling rule that places each training sample in only
ceil(qT)ofTtrees; - LZY, a lazy-tag mechanism that postpones subtree reconstruction until a later query actually traverses the affected path;
- ERT, an Extremely Randomized Tree base learner, chosen because randomized split candidates make the structure less sensitive to local sample changes.

Key formulaedit
The framework reduces the number of trees touched by each sample and amortizes tree repair over later queries. The following summary keeps the notation used in the paper: is the forest size, is the occurrence factor, and .
The OCC rule limits how many trees contain each sample:
The resulting training-time scaling is:
The expected unlearning speedup from OCC() is summarized as:
Exact unlearning is stated as distributional equivalence between unlearning and retraining without the removed sample:
The lazy-tag mechanism then turns a potentially large subtree retraining operation into path-level reconstruction only when a future query reaches the tagged node.
Resultsedit
The OpenReview paper reports that DynFrs achieves orders-of-magnitude faster unlearning than existing random-forest unlearning methods while preserving or improving predictive accuracy. In the PDF, the authors report a 4000 to 1,500,000 times speedup relative to naive retraining, a 22 to 523 times speedup relative to DaRE in sequential unlearning, and online mixed-stream latency of about 0.12 ms for modification requests and 1.3 ms for querying requests on a large-scale dataset.
The empirical results also distinguish sequential and batch unlearning. DynFrs is presented as the only evaluated random-forest method that remains strong in both settings, because OCC(q) reduces per-sample tree coverage while LZY prevents every deletion from triggering full subtree reconstruction.
Placementedit
This work belongs to Machine Unlearning, Random Forest, and Trustworthy AI. In Qiao's publication record, it complements Hessian-Free Online Certified Unlearning by focusing on exact unlearning for tree ensembles rather than approximate certified unlearning for differentiable models.