样本选择偏差何以促成模型坍缩edit
ICML 2026 论文,研究低资源验证场景、样本选择偏差、模型坍缩与协作 Wasserstein 几何代理。
样本选择偏差何以促成模型坍缩 是 乔鑫宝、Xianglong Du、Wei Liu、Jingqi Zhang、Peihua Mai、张萌和 Yan Pang 的 ICML 2026 会议论文。论文研究数据孤岛中的低资源验证场景如何把样本选择从模型坍缩的防护机制转化为加速坍缩的机制,以及协作分布代理如何缓解该失效模式。
概述edit
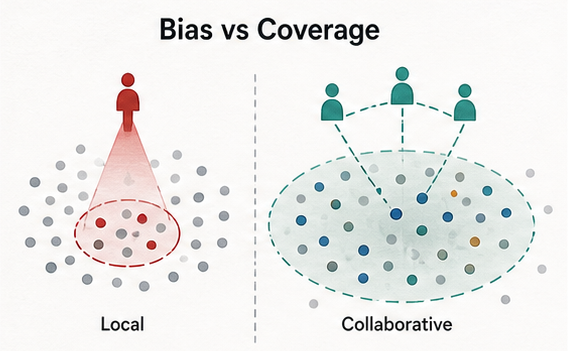
论文研究递归合成数据训练中的 模型坍缩。已有工作常把数据选择视为稳定工具:验证器过滤生成样本,只让高质量合成数据进入下一轮训练。本文反过来把验证器本身作为分析对象。当验证器只看到目标分布中小规模、碎片化且有偏的局部切片时,选择会反复奖励靠近本地视角的样本,并删除未来生成器所需的全局相关尾部模式。
动机设置是低资源数据孤岛。医疗联合体、银行或专有机构可能因为原始数据不能汇集,只能使用自身有限参考数据评估合成样本。选择因此变成一种确认偏差机制:接近本地视角的样本被保留,而稀有但有效的模式被剪掉。新版论文尤其强调低资源社区更脆弱:尾部区域在合成数据增强开始前就已经代表不足,本地过滤会把数据稀缺放大为持续性的覆盖损失。
方法edit
论文首先在 Gaussian 建模下形式化有偏 top- 选择,并把它与递归代际中的方差坍缩联系起来。随后提出协作评估方法,用多方计算的分布代理替代单个本地验证器,并且不交换原始数据。方法上的转变是:从单个低资源孤岛判断样本质量,转向评估合成池与全局目标代理分布的拟合程度。
论文描述了两个方案:
- Scheme I:协作测地插值,在合成分布与本地真实分布之间的 Wasserstein geodesic 上构造代理测度;
- Scheme II:协作 Wasserstein barycenter 估计,为集体参考分布计算可复用的 barycenter 代理。
两个方案都使用 Wasserstein-gradient-based sample scoring,使合成样本由多方分布参考评估,而不是由一个有偏孤岛评估。
关键公式edit
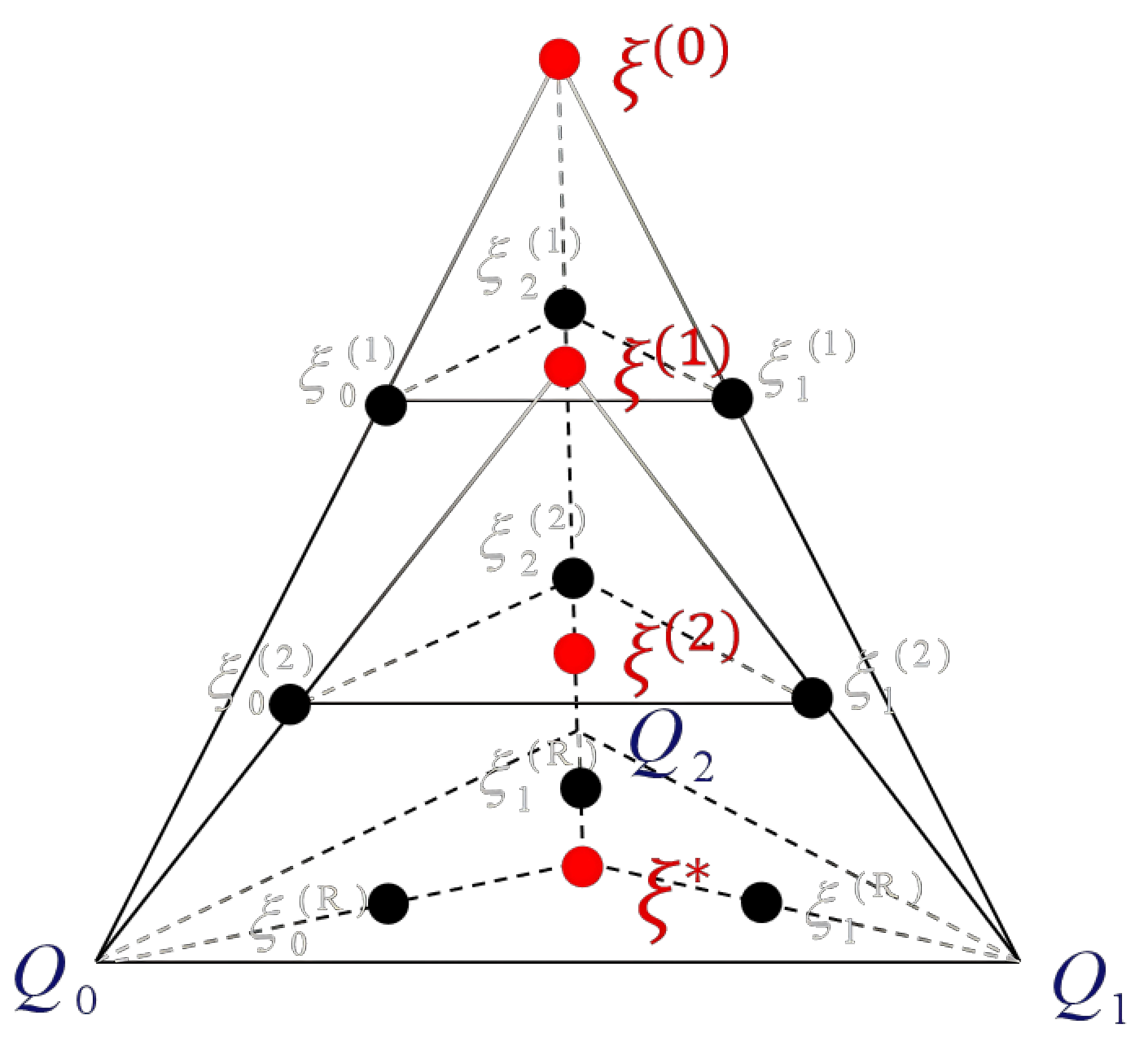
论文理论连接局部选择、多样性衰减和 Wasserstein 代价。设 为被选中的 top- 区域, 为第 代过滤后的合成分布, 为目标分布。
本地验证器选择可概括为截断采样:
由此导致的多样性衰减可通过协方差迹表示:
Wasserstein 泛化界将目标分布风险与过滤分布联系起来:
协作评分规则可通过对偶势函数 理解:
这些公式说明论文的主要机制:有偏选择会让保留分布越来越窄,而协作 Wasserstein 代理试图减少过滤合成数据与全局目标分布之间的差距。
结果edit
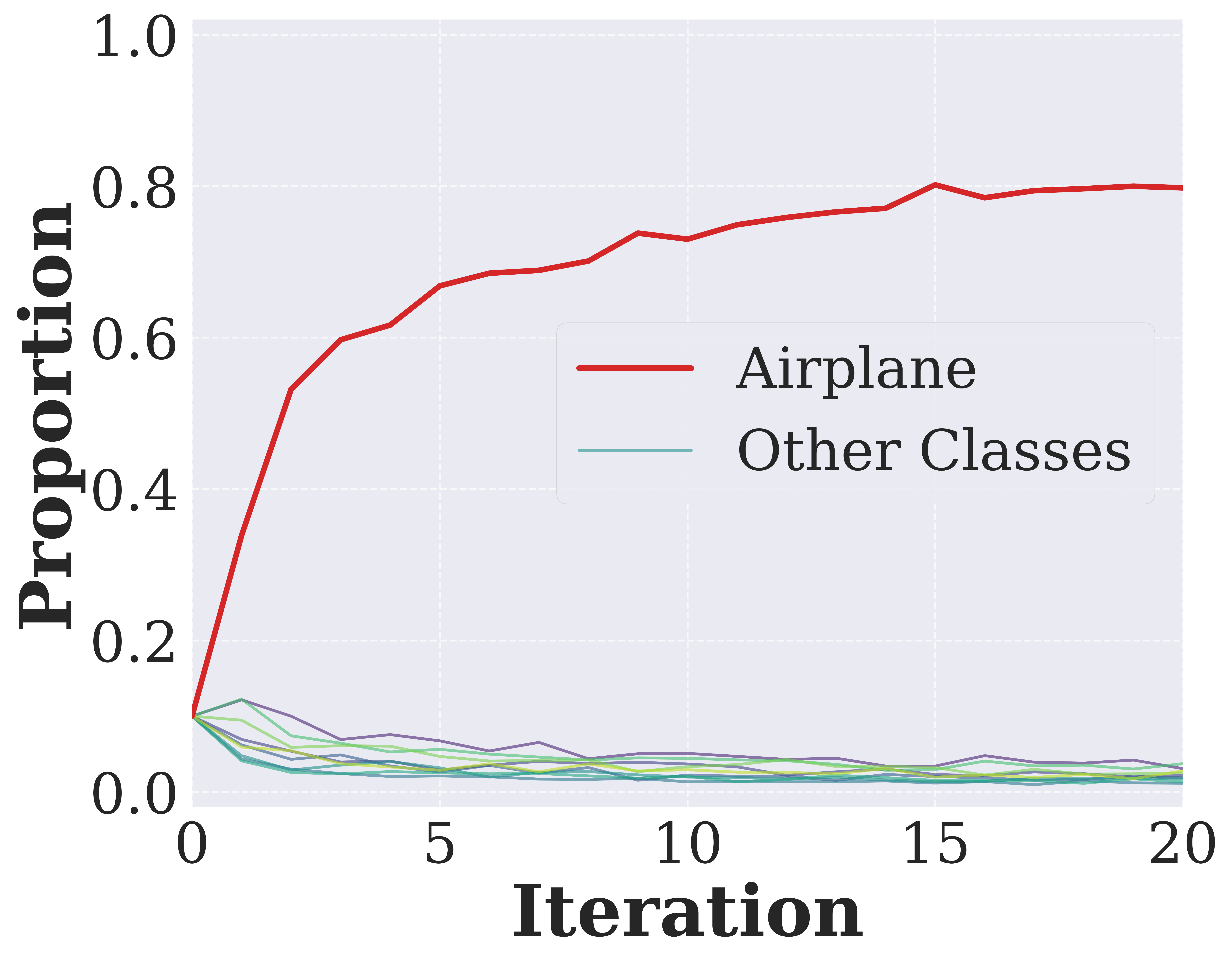
手稿报告了 CIFAR-10、STL-10 和 CelebA 上的 DDPM 风格递归图像生成实验。基线包括 Random selection、K-means、CenterMatch 和 CovMatch。在非 IID 或本地偏斜参考下,本地选择基线可能落后于随机选择;协作方案则能更好保持样本质量和模式覆盖。
核心结论是:低资源场景并不是高资源场景的简单缩小版。当真实数据覆盖稀缺或碎片化时,尾部模式本来就难以观测;本地参考选择会把稀有但有效的样本误认为低质量生成,从而系统性压制目标分布中代表不足的区域。附录中的 topic-local LLM 验证实验从语义角度支持了同一机制:用狭窄本地主题进行过滤,可能削弱 held-out 主题覆盖,而不是保护它。
定位edit
该工作属于 合成数据、合成数据(概念)、递归合成数据训练、数据选择、样本选择偏差、数据孤岛、协作评估 和 Wasserstein 几何。它是乔鑫宝机器遗忘论文的合成数据对应面:不是问训练后如何删除数据,而是问训练前的数据选择和验证如何塑造未来训练流。低资源强调也把该论文与模型坍缩的社会维度连接起来:分布尾部损失可能对应文化、语言或机构中代表不足内容的消失。